Aunque Hong Kong es pequeño comparado con otros países, sus multimillonarios en Bienes Raíces han acumulado una riqueza de 132 mil millones de dólares.
Solo son superados por Estados Unidos, que tiene 192 mil millones de dólares en Bienes Raíces.
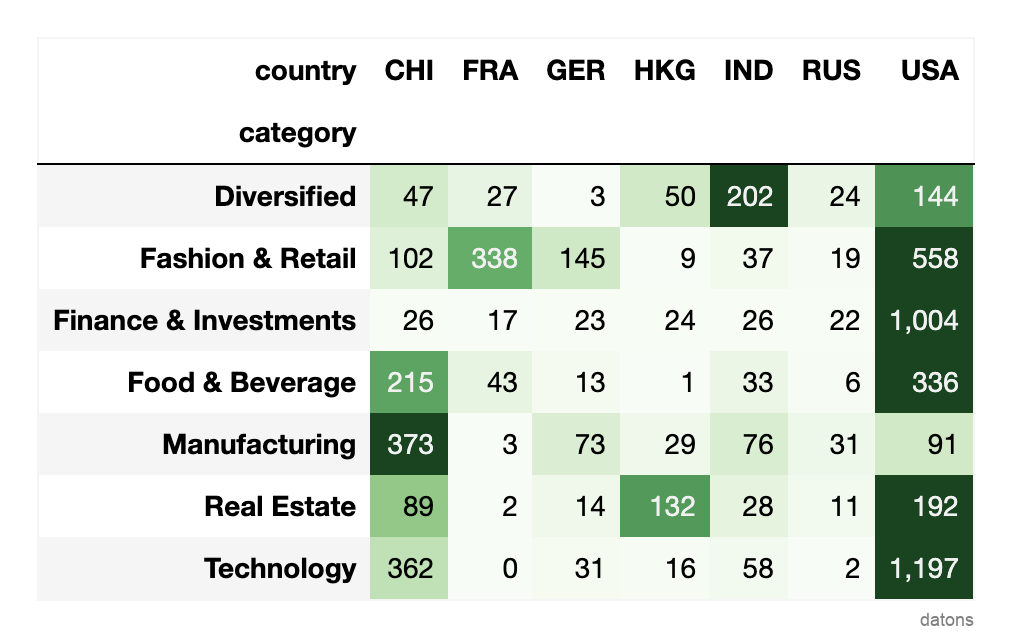
¿Cómo podemos construir una matriz de calor así desde un dataset en formato largo?
Datos
Cada fila representa un multimillonario, y las columnas representan sus atributos.
El dataset es un subconjunto del dataset original de multimillonarios de Kaggle.
df = pd.read_csv('data.csv')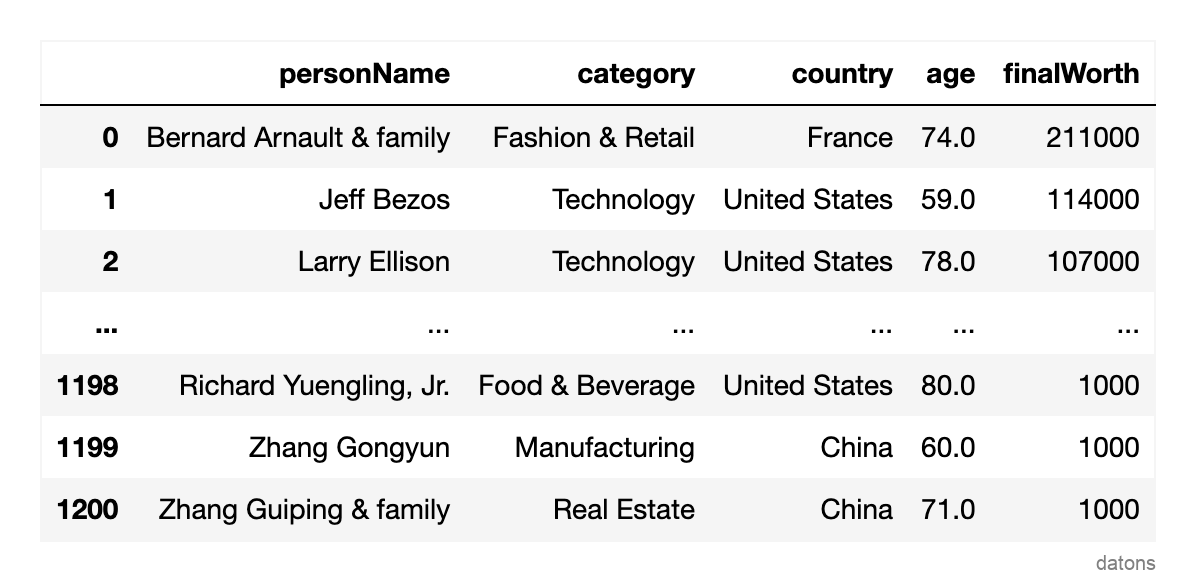
Preguntas
- ¿Qué es una tabla pivote de Pandas y cómo se usa en análisis de datos?
- ¿Cómo puedes resumir el valor total por país y categoría?
- ¿Cómo estilizar un
DataFramepara crear una matriz de calor? - ¿Por qué es crucial el formato de una matriz de calor para una legibilidad óptima?
- ¿Qué insights se pueden derivar del análisis de la matriz de calor?
Metodología
Tabla pivote para resumir categorías
Para resumir los datos en categorías, podemos usar la función pivot_table, configurando sus parámetros de la siguiente manera:
index: la columna categórica cuyas categorías serán representadas únicamente por las filas de la tabla resultante.columns: la columna categórica cuyas categorías serán representadas únicamente por las columnas de la tabla resultante.values: la columna numérica sobre la cual se aplicará una operación matemática.aggfunc: la operación matemática a aplicar a los valores.
Usando nuestro dataset, aplicamos la función pivot_table para responder la siguiente pregunta: ¿Cuál es el valor total de los multimillonarios por país y categoría?
dfr = (df
.pivot_table(
index='category', columns='country',
values='finalWorth', aggfunc='sum'
)
)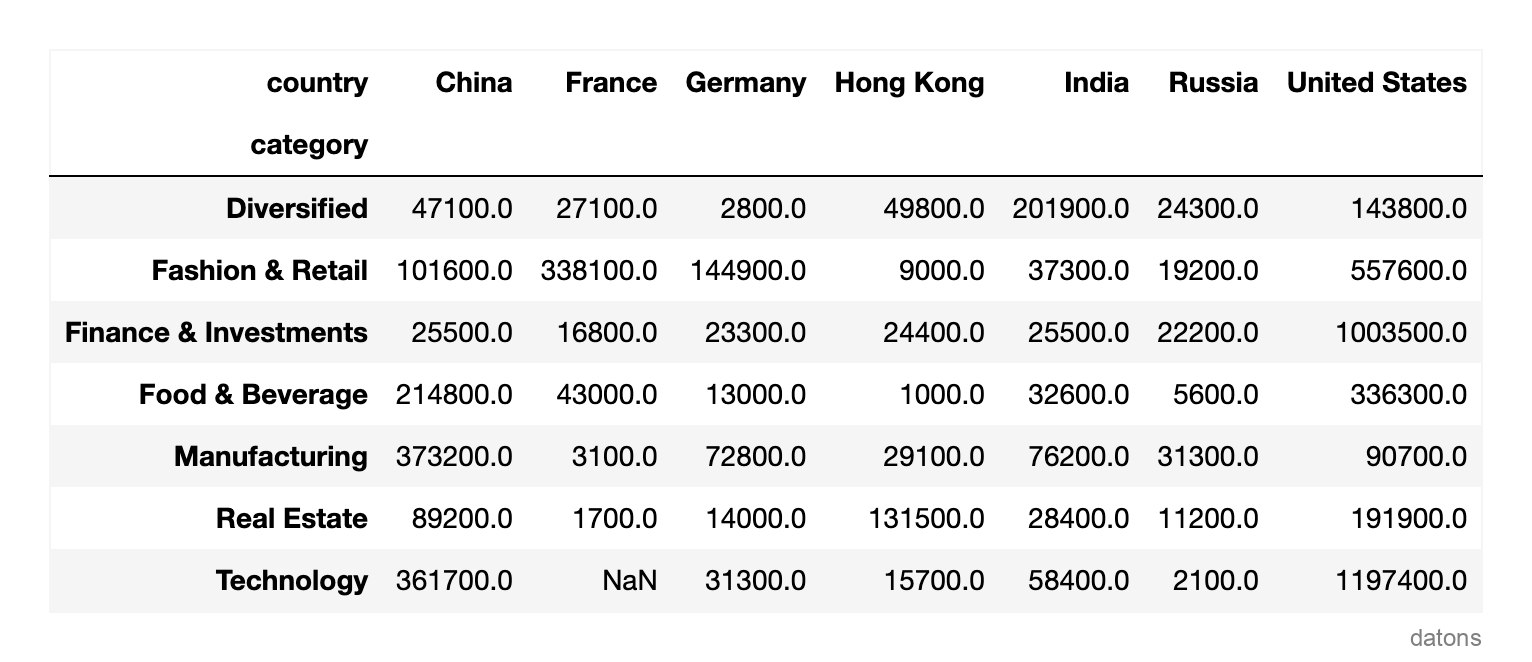
Habiendo resumido los datos, podemos comenzar a analizarlos. Sin embargo, la tabla no resalta visualmente qué países tienen el mayor valor total.
Abordemos esto coloreando las celdas de la tabla con una escala de colores de gradiente.
Matriz de calor con gradiente de fondo
dfr.style.background_gradient()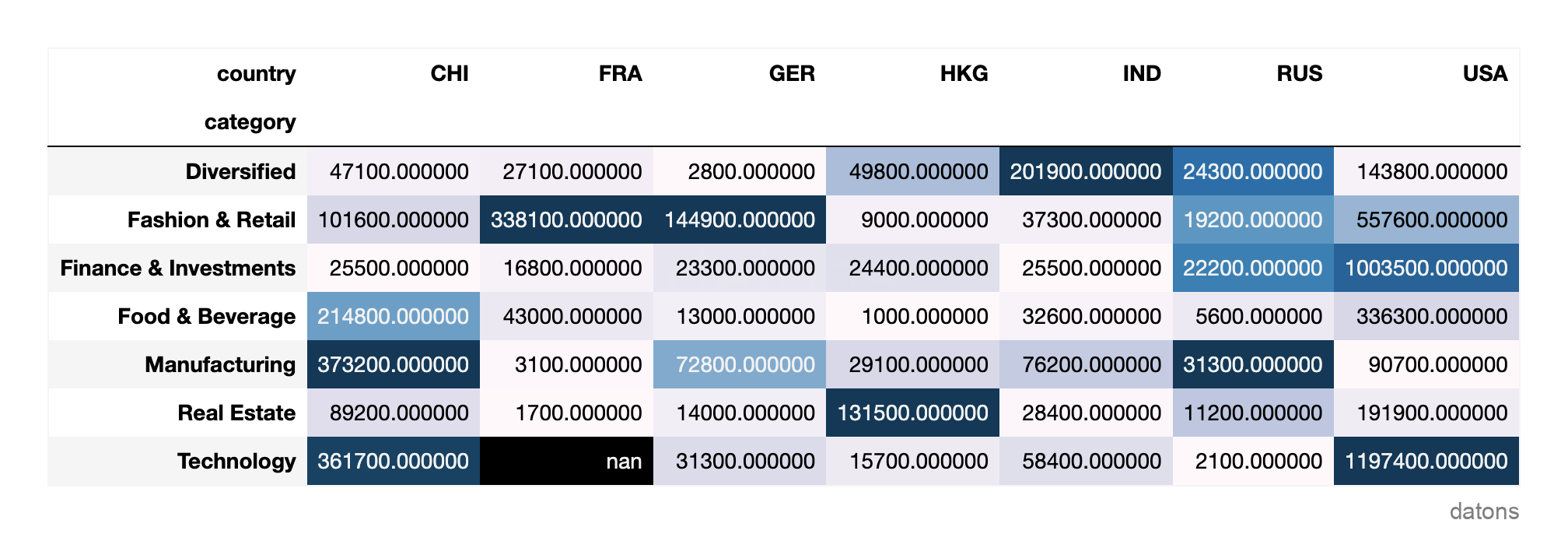
Hmm… ahora resalta las celdas con los valores más altos, pero es muy difícil discernir el patrón general.
Formateando la matriz de calor para legibilidad óptima
Para hacer la matriz de calor más atractiva, haremos lo siguiente:
- Rellenar valores faltantes con 0.
- Dividir los valores por 1,000 para mejorar la legibilidad.
- Formatear los números para incluir comas y omitir decimales.
- Reaplicar el gradiente con el esquema de colores ‘Greens’ para simbolizar billetes de dólar.
(dfr
.fillna(0)
.div(1_000)
.style
.format(precision=0, thousands=',')
.background_gradient(cmap='Greens', axis=1)
)¿Sería esto interesante para alguno de tus amigos? Compártelo con ellos.
La mayor parte del patrimonio neto está concentrado en EE.UU., aunque es notable cómo los fabricantes de China han acumulado una riqueza cuatro veces mayor que la de los de EE.UU.
¿Qué otros insights puedes detectar? ¡Comparte tus pensamientos en los comentarios!
Conclusiones
- Tabla pivote de Pandas: Usa
df.pivot_tablepara resumir y analizar patrones de datos eficientemente. - Resumir categorías: Identifica variables categóricas para análisis y aplica operaciones matemáticas a variables numéricas.
- Crear una matriz de calor: Emplea
df.style.background_gradientpara diferenciación visual de valores. - Formato óptimo: Ajusta unidades con
divy simplifica números usandodf.style.format. - Derivar insights: Analiza insights comparando filas y columnas contra la escala de colores.
Me encantaría escuchar tus pensamientos para mejorar aún más nuestros futuros artículos.
¿Qué encontraste más interesante o valioso en esta pieza?
¿Hay temas específicos o aspectos que te gustaría que profundicemos en nuestras próximas publicaciones?
Tu feedback es crucial para que proporcionemos mejor contenido que se alinee con tus necesidades e intereses.
¡Gracias por tu atención y apoyo!
Sigue leyendo
Artículos relacionados que te pueden interesar

Desapilar dataframe después de agrupar para crear matriz de calor
Tutorial de Python para desapilar las categorías de filas en columnas (tabla larga a ancha) para luego crear una matriz de calor.
Leer
Principales diferencias entre matplotlib, seaborn y plotly
¿Qué biblioteca deberías usar para visualización de datos en Python? ¿Matplotlib, Seaborn o Plotly? Aprende las principales diferencias entre ellas y cuándo usar cada una.
Leer
Programar órdenes de trading con la API de Alpaca en Python
Aprende a automatizar estrategias de trading programando órdenes de compra y venta con Python usando la API de Alpaca.
Leer