La siguiente tabla representa una matriz de calor que resalta la cantidad total de electricidad, en teravatios-hora (TWh), producida por cada fuente dentro de la red eléctrica US48 durante 2023.

Para crear la matriz de calor desde el dataset sin procesar, que típicamente viene en formato largo, necesitamos aplicar varios pasos que se cubrirán en este tutorial.
Antes de comenzar, entendamos el dataset con el que estamos trabajando.
Datos
La red eléctrica de EE.UU. produce electricidad de varias fuentes, como gas natural, solar y petróleo, cada hora. La cantidad de electricidad producida por cada fuente se registra en cada fila del dataset.
Los datos son proporcionados por la Administración de Información Energética de EE.UU. (EIA). Consulta este tutorial para aprender cómo recuperar los datos de la API de EIA.
import pandas as pd
df = pd.read_csv('data.csv')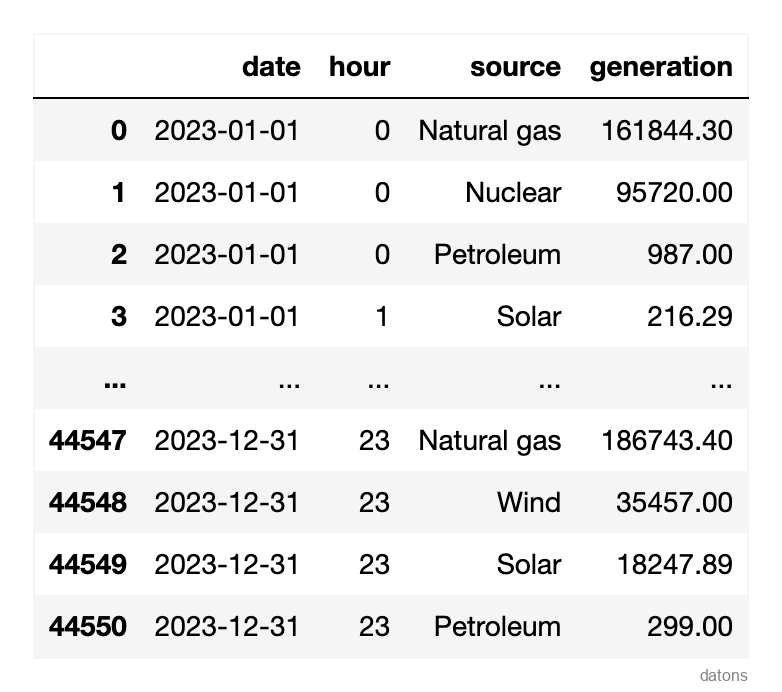
Preguntas
- ¿Cómo podemos transformar un DataFrame de formato largo a ancho?
- ¿Qué función resume datos en categorías?
- ¿Cómo visualizamos tendencias de datos a través de una matriz de calor?
Metodología
GroupBy para resumir datos en categorías
Antes de escribir el código para agrupar los datos, considera qué columnas son categóricas y cuáles son numéricas:
- Las columnas categóricas contienen las categorías para agrupar los datos.
- Las columnas numéricas contienen los valores sobre los que se aplicarán operaciones matemáticas.
En el análisis de generación de energía, es crucial identificar las fuentes utilizadas para producir electricidad cada hora. Esto ayuda a medir, por ejemplo, la tasa de utilización de fuentes renovables versus no renovables. Por lo tanto:
- Columnas categóricas:
hour,source - Columnas numéricas:
generation - Operación matemática:
sum
sr = df.groupby(['hour', 'source']).generation.sum()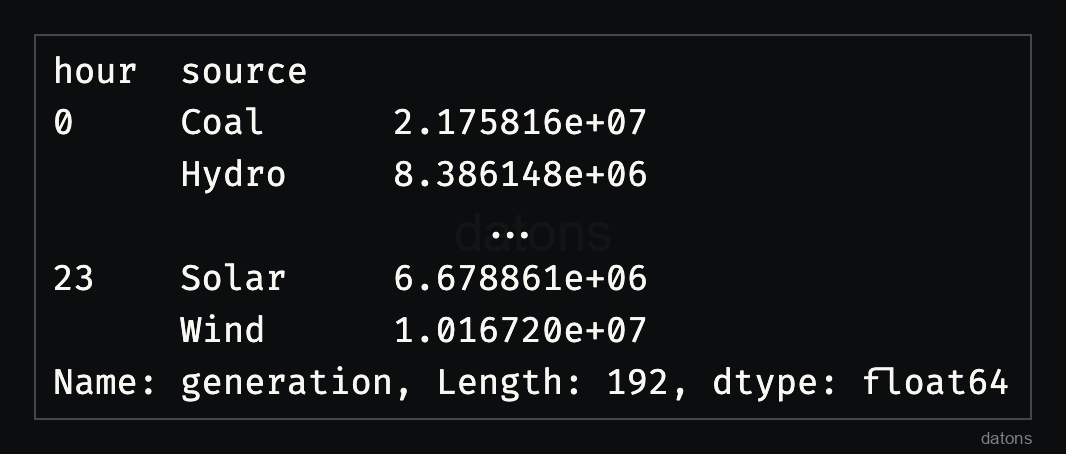
Con 192 filas distribuidas en 24 horas y [X] fuentes, ¿puedes detectar las diferencias? Es difícil a simple vista, así que desapilemos el DataFrame.
Desapilar categorías de filas a columnas
En lugar de tener las fuentes como filas, las desapilaremos (unstack) en columnas para una vista completa de la generación de energía por fuente y hora.
¿Sería esto interesante para alguno de tus amigos? Compártelo con ellos.
dfr = (df
.groupby(['hour', 'source'])
.generation.sum()
.unstack('source')
)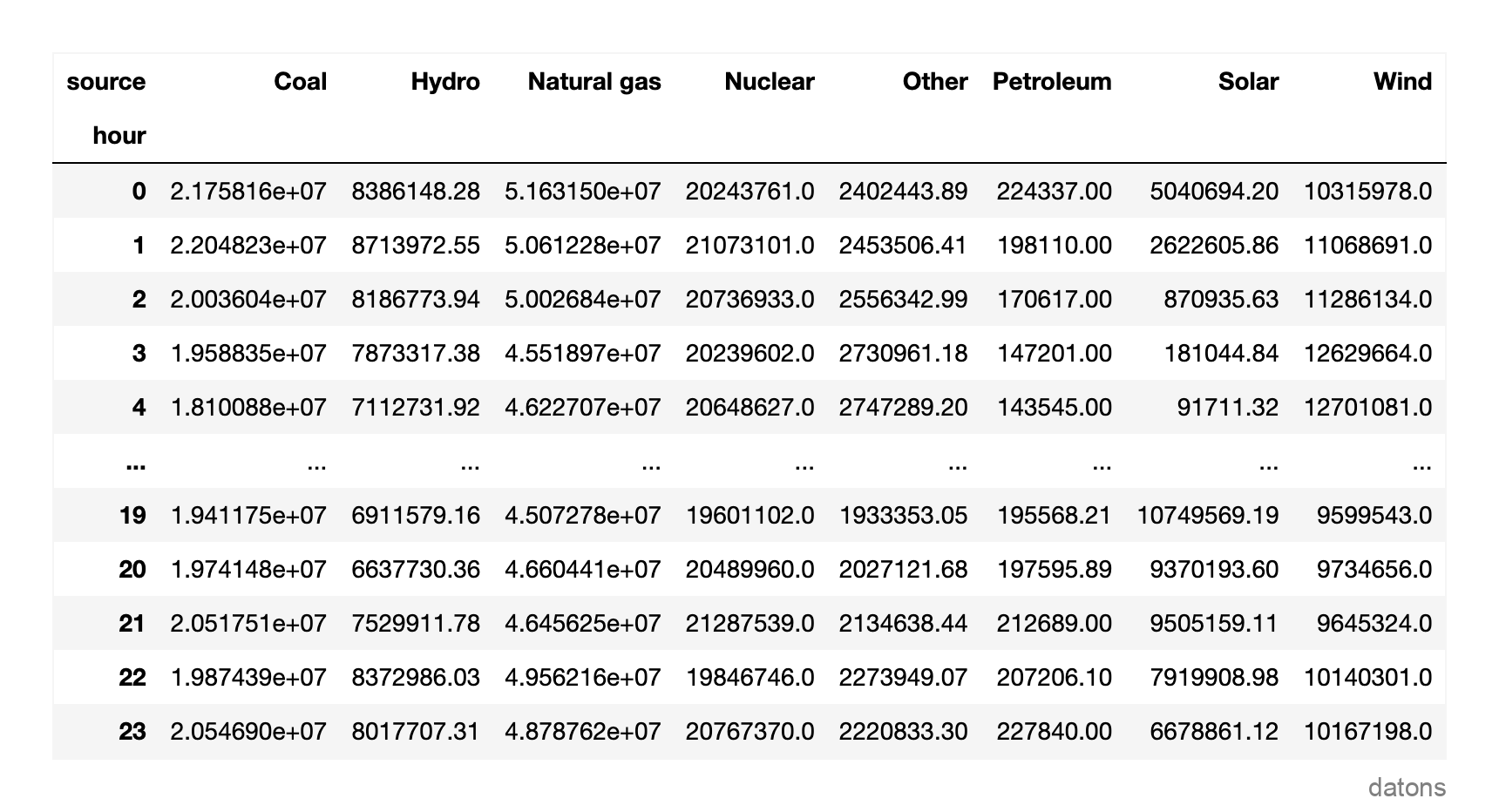
Ahora, tenemos una vista más compacta, pero todavía es difícil discernir qué fuentes son más utilizadas según la hora. Procedamos a crear la matriz de calor.
Matriz de calor con gradiente de fondo
Siguiendo las directrices de este tutorial sobre estilizar un DataFrame para crear una matriz de calor, resaltaremos los valores máximos en TWh (dividiendo por 1 millón ya que los valores están en MWh) con un fondo de gradiente.
Desde la matriz de calor, es observable que la producción de energía solar superó los 10 TWh desde la hora 17 hasta la 19.
¿Qué otros insights puedes detectar? ¡Te leo en los comentarios!
Conclusiones
- Transformación de largo a ancho: Desapilar filas en columnas transforma efectivamente el DataFrame, proporcionando una vista más clara y panorámica de los datos.
- Resumen de datos: Usar operaciones
groupbyysumpermite una categorización concisa de datos, esencial para el análisis. - Visualización de matriz de calor: Estilizar DataFrames con
background_gradientacentúa tendencias clave, haciendo los insights más accesibles.
En lugar de usar dos funciones: groupby y unstack, podrías utilizar la función pivot_table para lograr el mismo resultado. Consulta el tutorial aquí.
Me encantaría escuchar tus pensamientos para mejorar aún más nuestros futuros artículos.
¿Qué encontraste más interesante/valioso en esta pieza?
¿Hay algún tema que te gustaría que cubramos en el futuro?
Tu feedback es crucial para generar contenido de alta calidad que se alinee con tus necesidades e intereses.
¡Gracias de antemano por tu atención y apoyo!
Sigue leyendo
Artículos relacionados que te pueden interesar
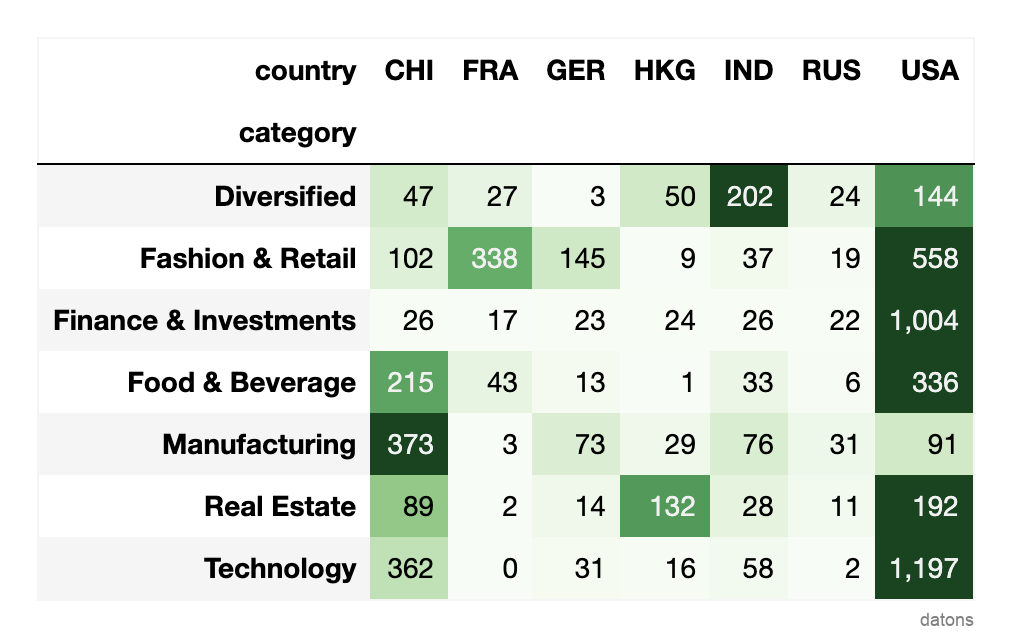
Estilizar tabla pivote para crear matriz de calor
Aprende cómo resaltar las celdas más valiosas en una tabla pivote de Pandas que resume información sobre multimillonarios por país e industria.
Leer
Principales diferencias entre matplotlib, seaborn y plotly
¿Qué biblioteca deberías usar para visualización de datos en Python? ¿Matplotlib, Seaborn o Plotly? Aprende las principales diferencias entre ellas y cuándo usar cada una.
Leer
Programar órdenes de trading con la API de Alpaca en Python
Aprende a automatizar estrategias de trading programando órdenes de compra y venta con Python usando la API de Alpaca.
Leer