Imagina que eres un inversor en energías renovables y deseas analizar el curtailment energético en España para evaluar la rentabilidad de construir un parque solar fotovoltaico.
El curtailment es la energía que, aún pudiendo ser generada, no lo es por restricciones técnicas impuestas por el operador del sistema eléctrico (REE en España) para mantener la estabilidad del sistema.
Por ejemplo, la unidad de programación FVGNRA sufrió un curtailment de 16,922.4 MWh durante el año 2023. Tirando por lo bajo, si el precio capturado por la energía fotovoltaica fuera de 20€/MWh, el curtailment supuso haber dejado de ganar 338,448 €.
Como inversor, debes considerar el curtailment para obtener mayor precisión en los cálculos de rentabilidad.
Contexto archivos I90
Localizar datos
Primero debemos encontrar los datos históricos de curtailment por unidad de programación energética, que se encuentran dentro de los archivos I90, proporcionados por el operador del sistema eléctrico (REE).
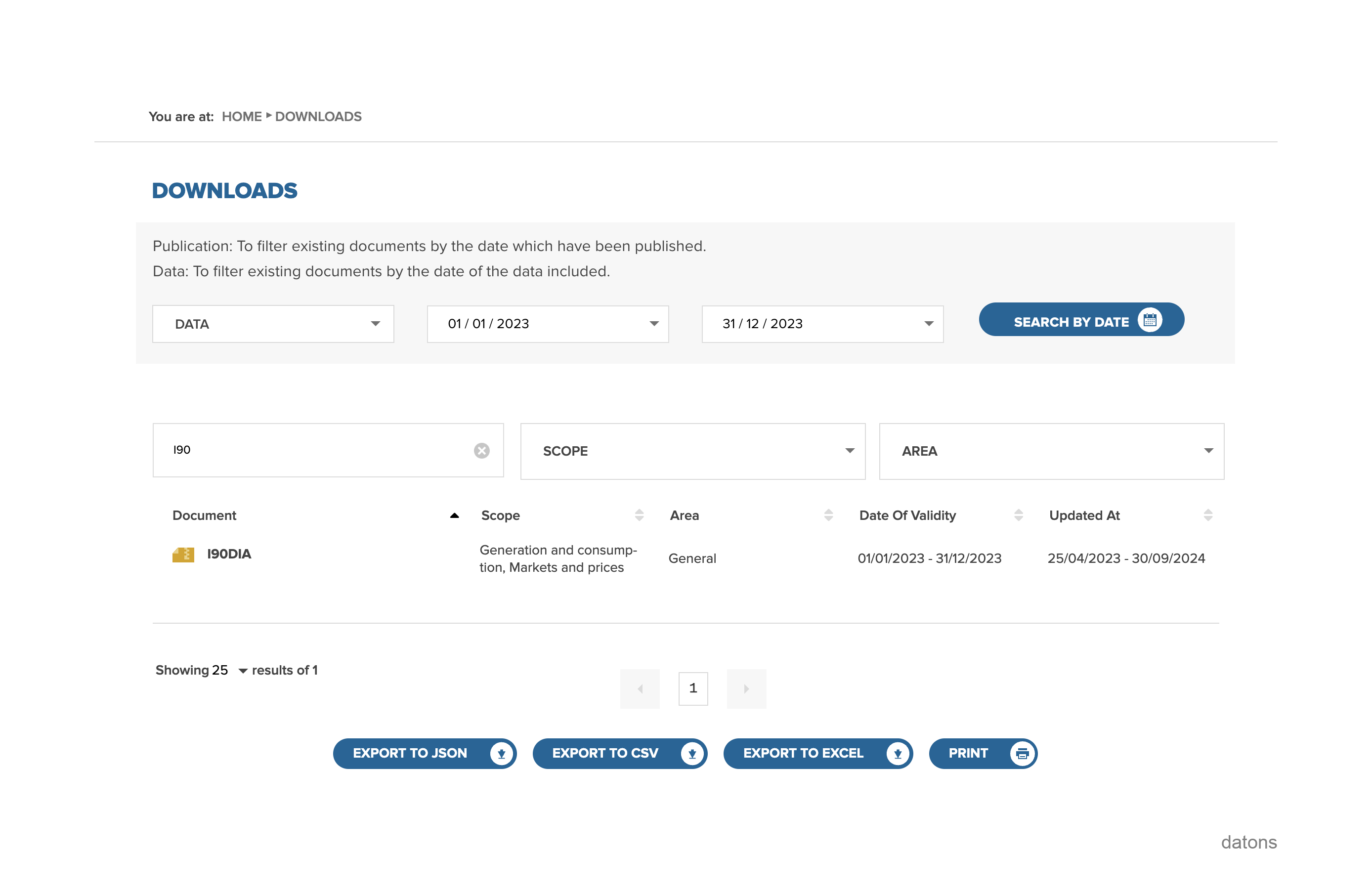
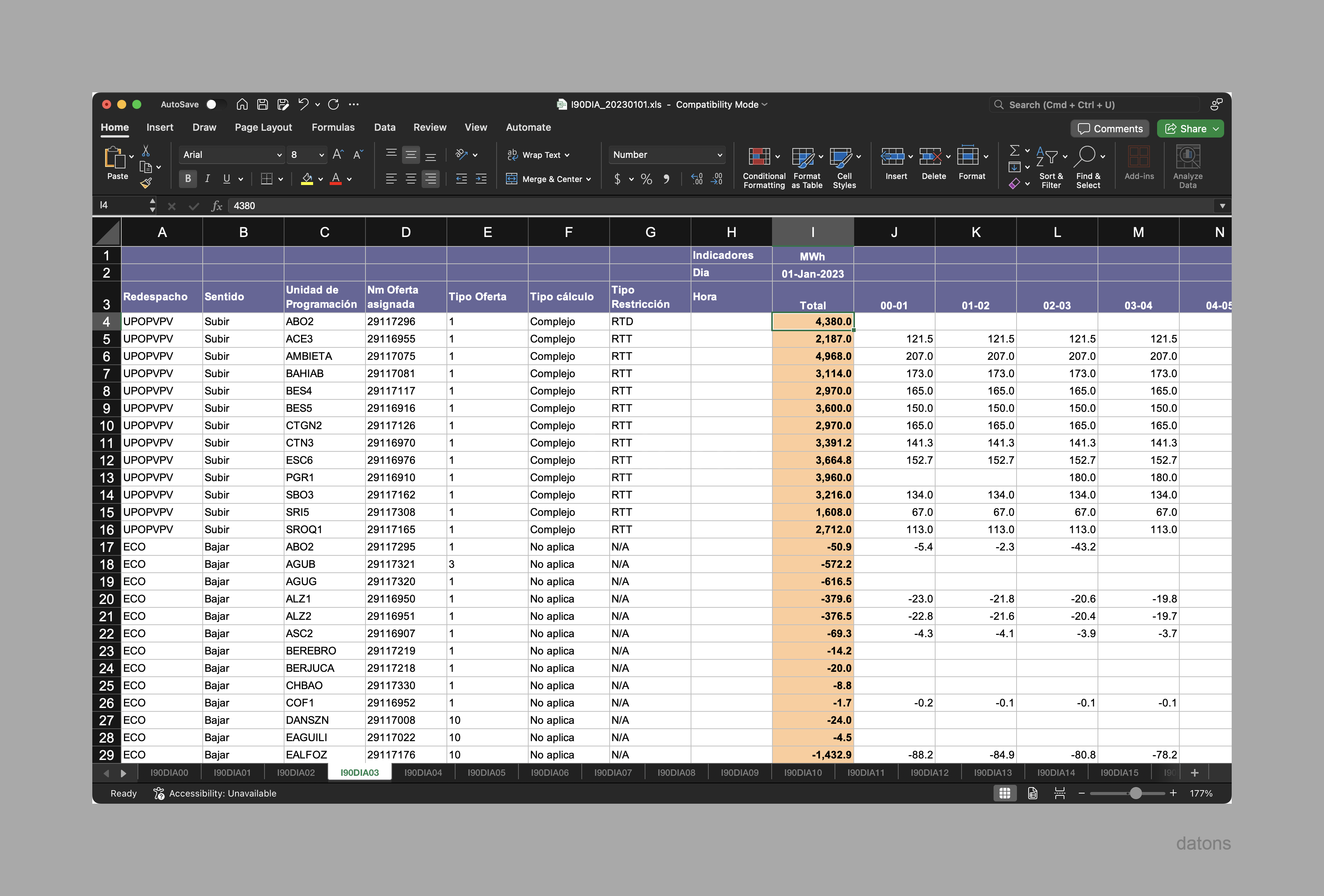
Los archivos I90 desglosan la información de cada unidad de programación energética según los programas de generación para cada día en un Excel.
Comprender estructura
Antes de meternos de lleno con la programación, debemos comprender la estructura de los archivos I90, que reparte la información por hojas separadas según el tipo de programa de generación, y tipo de medida (generación, precios y ofertas).
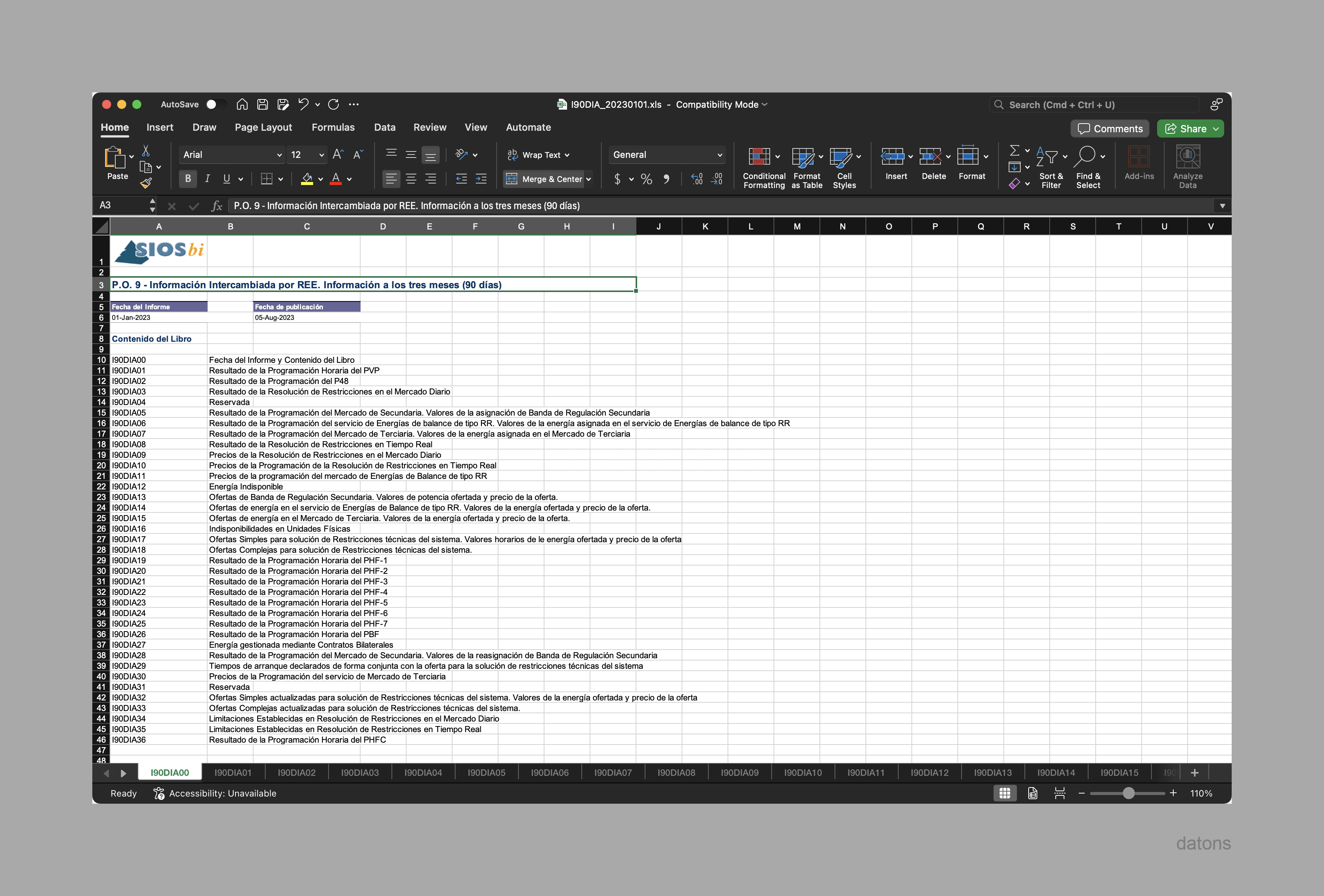
La información del curtailment se encuentra en la hoja I90DIA03: Resultado de la Resolución de Restricciones en el Mercado Diario, filtrando por Sentido: Bajar y excluyendo los tipos de -Redespacho:ECO.
Proceso de automatización
Diseñar proceso
Una vez localizada la secuencia de datos exacta que necesitamos, debemos diseñar el proceso de automatización.
Lo primero a tener en cuenta es que el Excel solo contiene la información de un día, por lo que el proceso debe ser replicable para cualquier archivo I90.
Una vez procesados todos los archivos I90, estos serán combinados en una misma tabla de datos, que nos permitirá manipular y analizar la información histórica. Por tanto:
- Crear función para preprocesar cualquier hoja del archivo I90.
- Combinar todos los archivos I90 en una tabla base.
- Exportar la tabla base a Excel para desarrollar múltiples análisis.
- Desarrollar múltiples análisis a partir de la tabla base.
Crear función para un archivo
Como todos los archivos I90 siguen una estructura similar, seleccionamos uno de ellos para desarrollar el proceso.
La tabla que proporciona el Excel está en formato ancho, segmentado por horas en cada columna y haciendo referencia a la misma variable (energía generada en una hora determinada).
Para manipular y analizar la información, debemos convertir la tabla a un formato largo, donde cada columna representa una variable. Es decir, agrupar las horas en una misma columna datetime y la energía generada en otra columna value.
path = "I90DIA/I90DIA_20230101/I90DIA_20230101.xls"
preprocess_i90_file(path, sheet_name="I90DIA03")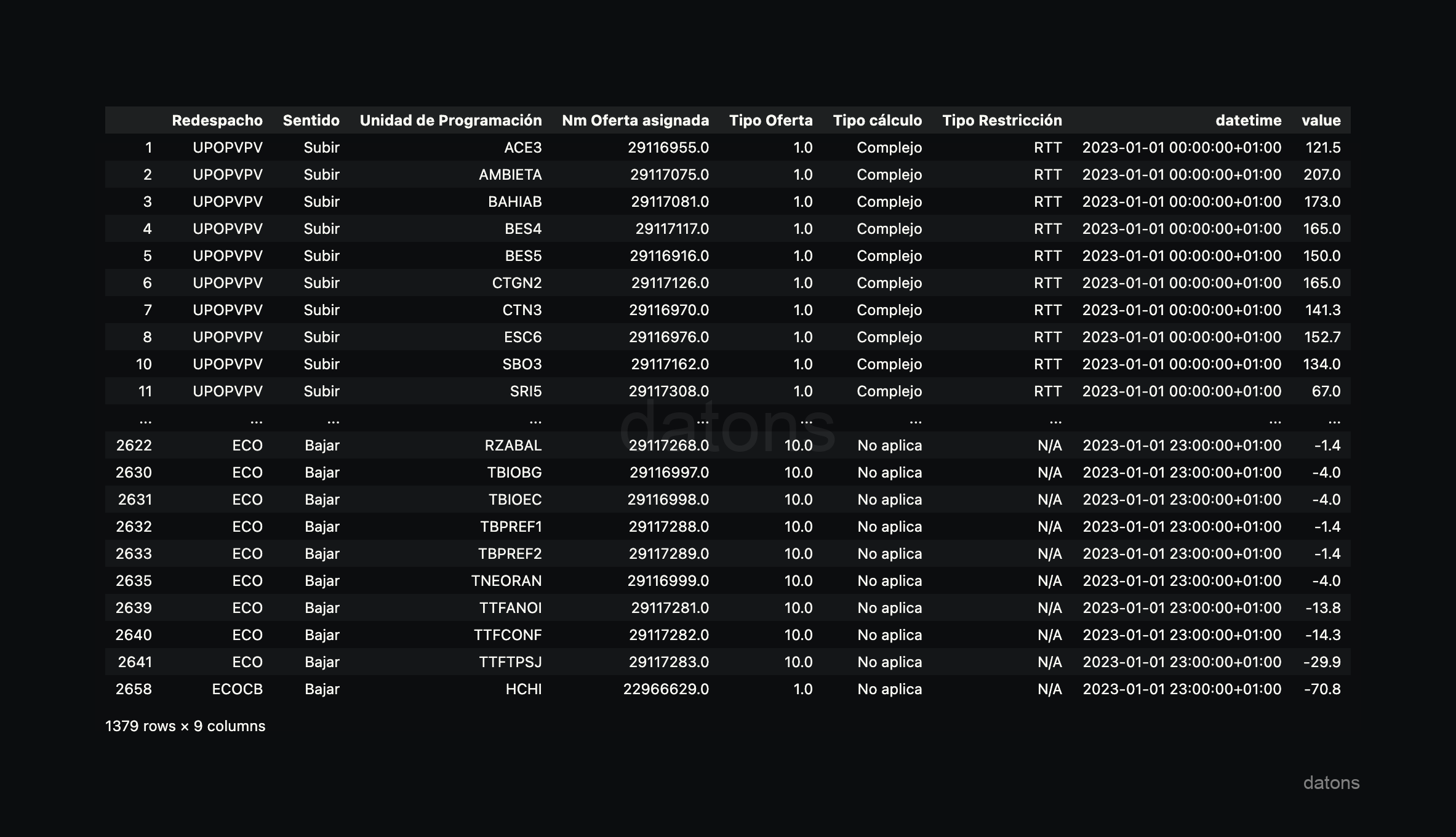
Combinar todos los archivos
Lo bueno de Python es que podemos aplicar la misma función a todos los archivos I90 para, finalmente, combinar todos los archivos en una sola tabla.
Primero, obtenemos la lista de archivos I90 para el año 2023, que se encuentran en la carpeta I90DIA.
import glob
path = "I90DIA/I90DIA_2023*/I90DIA_2023*.xls"
files = glob.glob(path)Ahora, aplicamos la función preprocess_i90_file sobre cada archivo a través de un bucle for, donde también almacenamos cada tabla en una lista para, finalmente, combinar todas las tablas en una sola.
dfs = []
for file in files:
dfs.append(preprocess_i90_file(file, sheet_name="I90DIA03"))
df = pd.concat(dfs)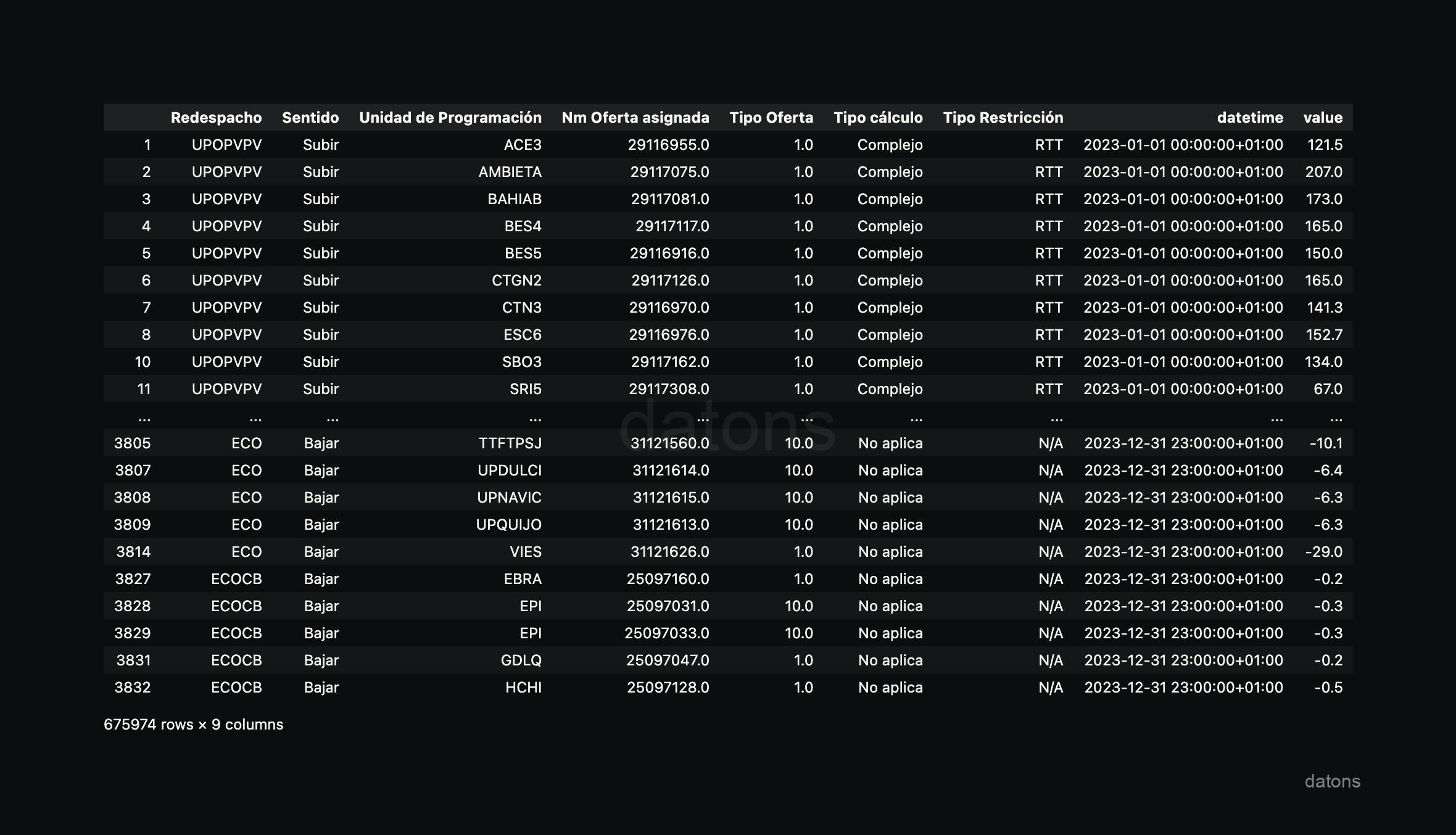
Si hubiéramos filtrado por Sentido: Bajar desde el principio, estaríamos perdiendo información que puede ser relevante para otros análisis y añadiríamos repeticiones.
Por tanto, no solo podríamos analizar el curtailment, sino que también podríamos analizar otros aspectos relevantes como Sentido: Subir, Redespacho o Tipo Restricción, entre otros.
Exportar datos a fichero
Para no tener que volver a preprocesar los datos al desarrollar un análisis, es recomendable exportar la tabla de Python a un archivo Excel.
df.to_excel("I90_2023.xlsx", index=False)Análisis de curtailment por unidad
Cargar datos
De la misma manera que hemos exportado los datos, podemos cargarlos en Python para desarrollar un análisis.
df_i90 = pd.read_excel("I90_2023.xlsx")Filtrar filas
En nuestro caso, queremos analizar el curtailment de la unidad FVGNRA, por lo que filtramos por sign: Bajar y unit: FVGNRA.
sign = "Bajar"
unit = "FVGNRA"
df_curtailment_unit = df_i90.query('sign == @sign & unit == @unit')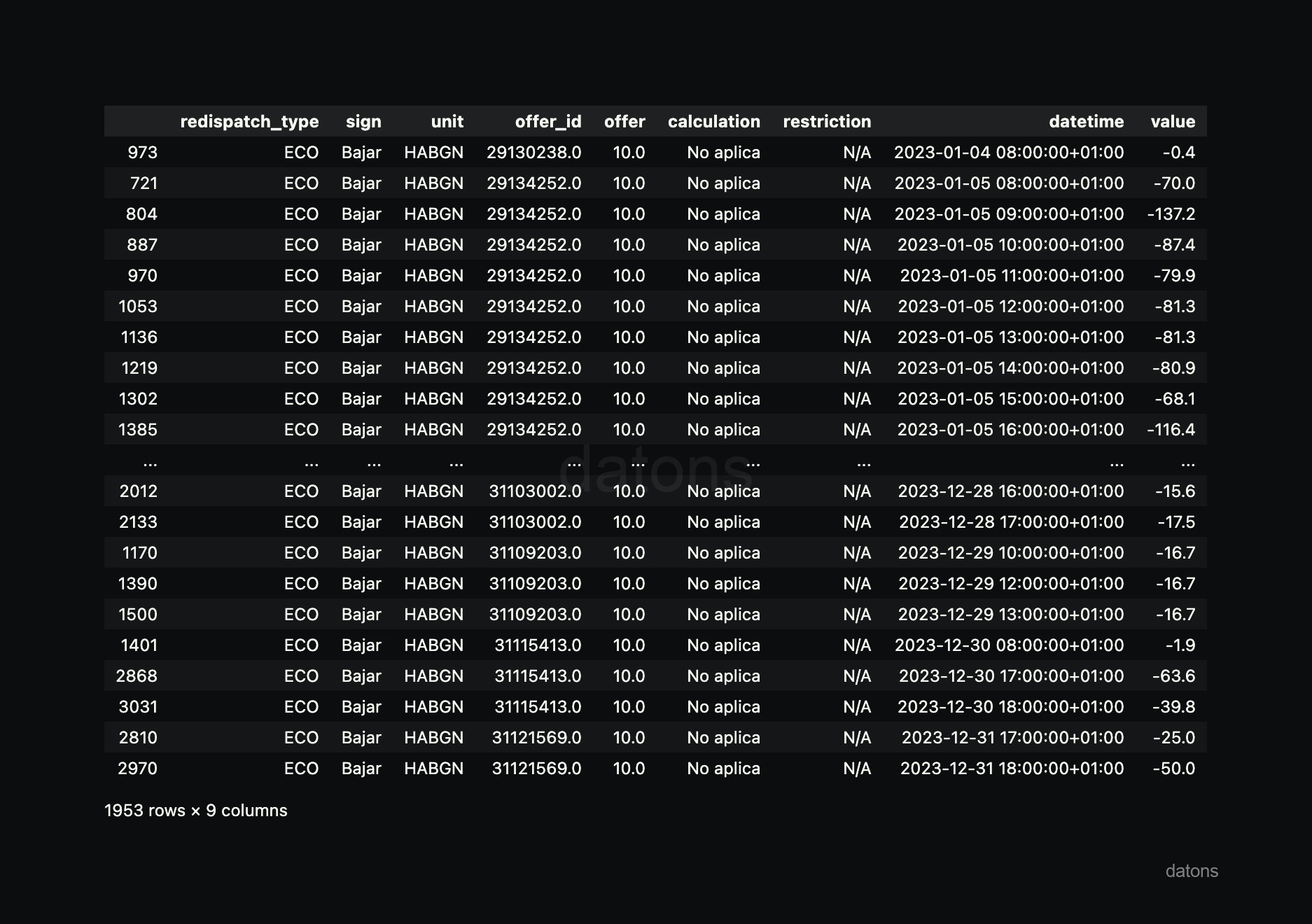
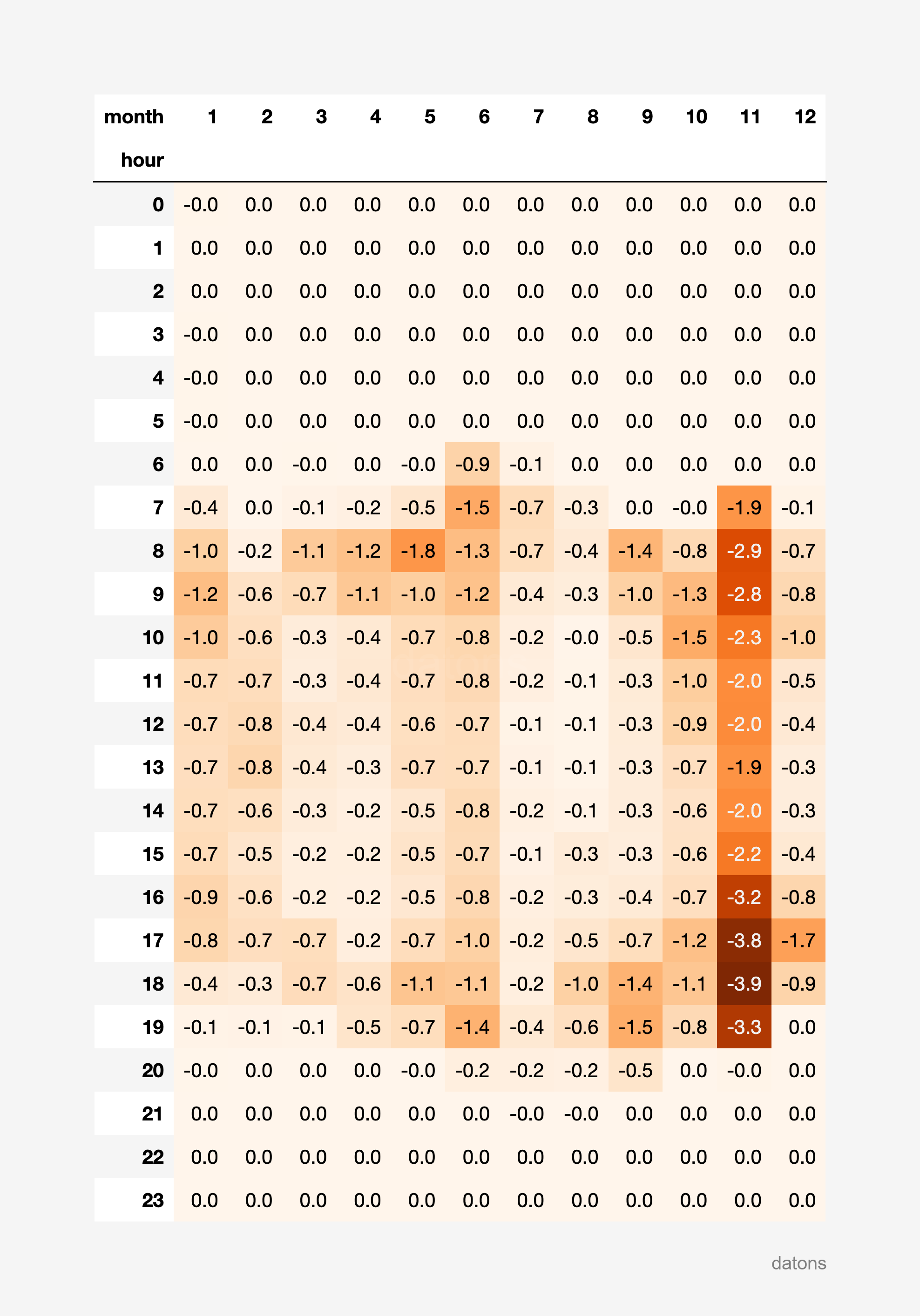
Matriz de calor
Para generar el reporte de curtailment por undidad, desarrollamos una función que genere una matriz de calor, donde se resaltan las horas y meses, en GWh, con mayor curtailment.
report_heatmatrix(df_curtailment_unit)Incluso podríamos ampliar la función para que acepte, como parámetro, la unidad sobre la que se quiere hacer el reporte.
report_heatmatrix_unit(df_i90, unit='FEGPEM')
Así es cómo Python nos permite automatizar y optimizar el proceso de análisis de datos. Pero no solo eso, sino que también podemos extender el proceso para analizar otros aspectos relevantes como el curtailment por tecnología.
Análisis de curtailment por tecnología
Cruzar múltiples tablas por columna común
En la tabla actual no tenemos la información de la tecnología asociada a cada unidad de programación energética. Por tanto, descargamos la tabla que contiene la información detallada de cada unidad de programación energética.
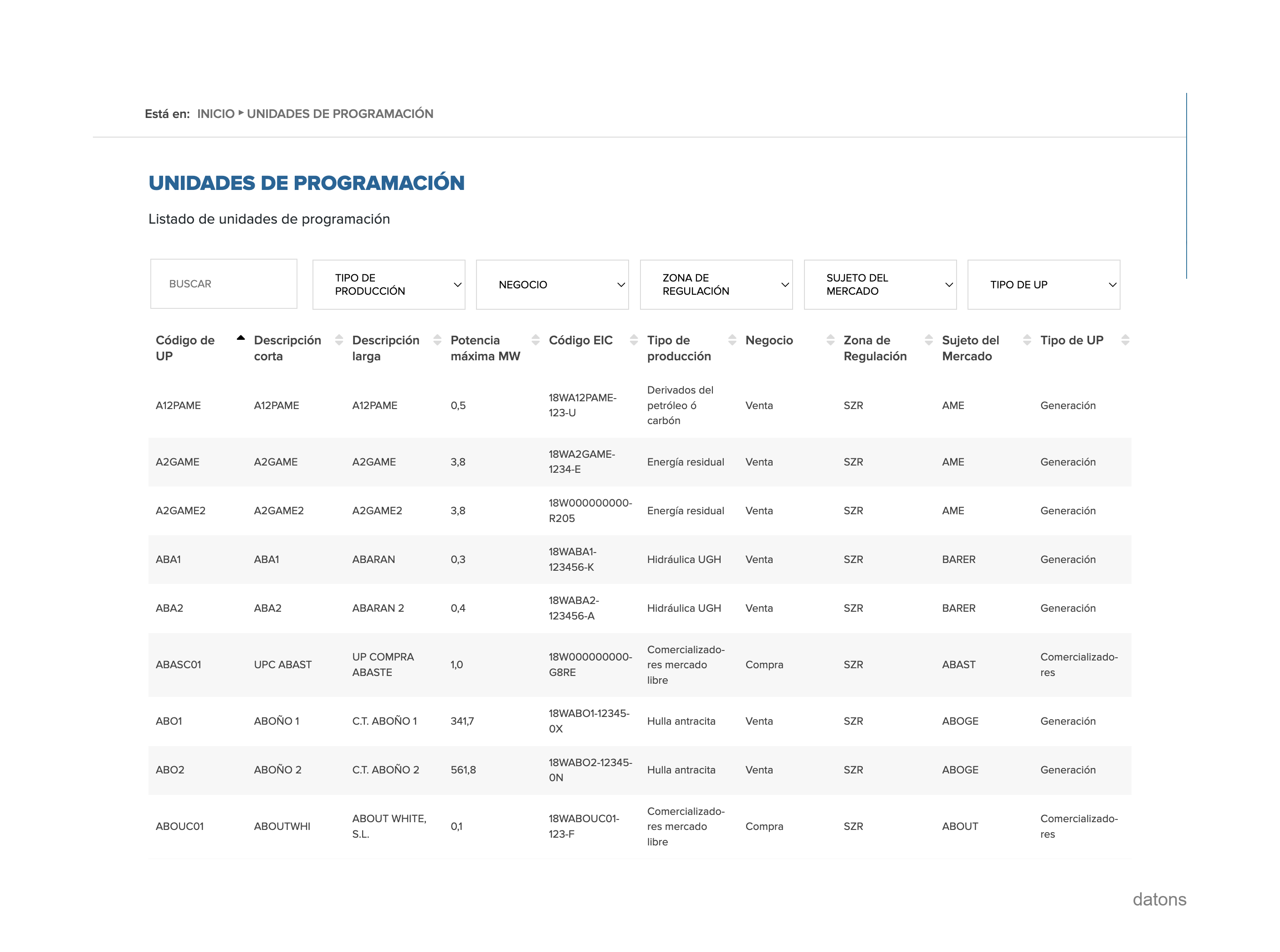
Y la cruzamos con la tabla procesada de los archivos I90.
df_i90_units = df_i90.merge(df_units, on="unit", how="left")Matriz de calor
En la misma medida que antes habíamos extendido la función para que aceptara la unidad, ahora la extendemos para que también pueda aceptar la tecnología.
report_heatmatrix(df_i90_units, technology="Solar fotovoltaica")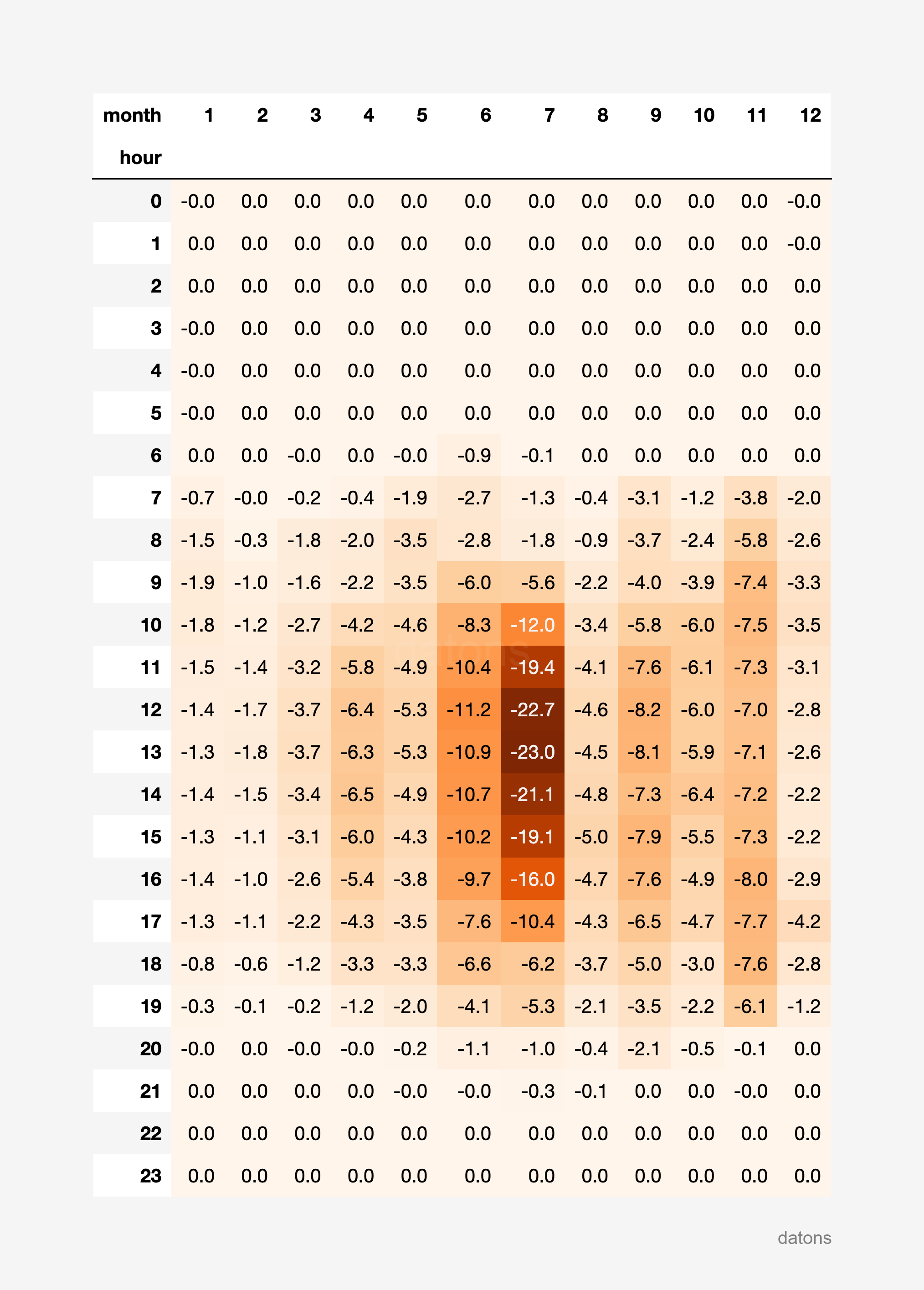
Y cómo no, podemos aplicar la misma función para cualquier tecnología. Veamos el curtailment de la tecnología Eólica.
report_heatmatrix(df_i90_units, technology="Eólica")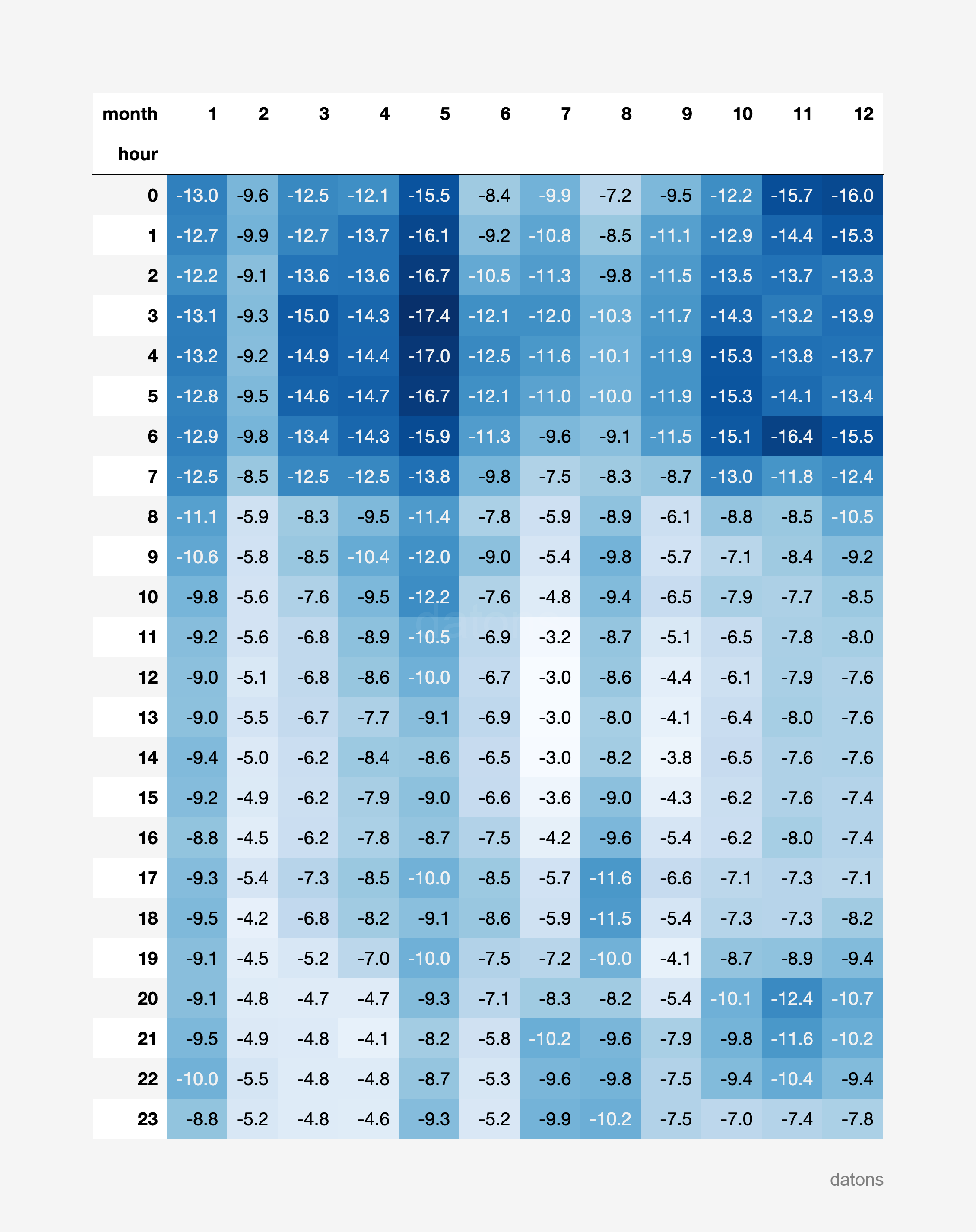
Resulta que la energía eólica presenta un curtailment más acentuado en las horas de la noche durante todo el año, mientras que la energía solar fotovoltaica presenta un curtailment más acentuado en las horas de la mañana y la tarde durante los meses de verano.
Conclusiones
- Automatización y escalabilidad: Al diseñar una función de preprocesamiento y aplicarla a múltiples archivos, se logra un flujo automatizado que evita tareas repetitivas en Excel.
- Estandarización de formatos: Convertir los datos de formato ancho a largo facilita la manipulación y el análisis, permitiendo un manejo uniforme de la información.
- Mayor flexibilidad analítica: La posibilidad de combinar distintos conjuntos de datos y de filtrar o agrupar información en Python proporciona una visión más completa y ágil que depender de hojas de Excel separadas.
- Procesos reproducibles: Los scripts en Python hacen que todo el proceso sea auditado y replicable, ahorrando tiempo en futuras iteraciones o con datos adicionales.
- Generación de reportes: A partir de la tabla consolidada, se pueden generar reportes personalizados (matrices de calor, análisis comparativos, etc.) y exportarlos de vuelta a Excel para su distribución.
Sigue leyendo
Artículos relacionados que te pueden interesar
Ejecutar scripts en piloto automático cada día para actualizar base de datos con GitHub Actions
Teniendo una base de datos que necesita ser actualizada con los nuevos datos que se publican cada día, ¿cómo automatizar la ejecución de scripts con GitHub Actions?
Leer
Base de datos normalizada para consultar los archivos I90
Comprende el proceso para crear una base de datos normalizada donde consultar la información histórica de las unidades de programación energética del sistema eléctrico español con ejemplos prácticos.
Leer
Análisis de datos del mercado eléctrico español con archivos I90
Descarga, procesa y analiza archivos I90 de REE con Python — tendencias de curtailment, mix de generación y correlación con precios del mercado eléctrico español.
Leer